Benvenuti
Riassunto
L'obiettivo del progetto MOLTO è quello di sviluppare una serie di strumenti per la traduzione di testi in più lingue, in tempo reale, mantenendone la qualità alta. Le diverse lingue sono organizzate in moduli separati e possono essere modificate indipendentemente. I vari prototipi costruiti durante il progetto copriranno la maggior parte della 23 lingue ufficiali dell'Unione Europea.
Come la sua tecnica principale, MOLTO utilizza grammatiche semantiche per specifici contesti ed interlingua basate su ontologie. Queste componenti sono implementate in GF (Grammatical Framework), che è un formalismo grammaticale ove più lingue vengono messe in relazione attraverso una sintassi astratta comune. GF è stato applicato in diversi contesti di piccole e medie dimensioni, in genere utilizzando fino a dieci lingue, ma il progetto MOLTO si prefigge di poter migliorare questo dato in termini di produttività e di applicabilità.
Parte del miglioramento deriva dall'aumento della dimensione dei contesti e del numero di lingue. Ma il miglioramento più sostanziale si otterrà col rendere la tecnologia accessibile agli esperti di un contesto privi di esperienza in GF e nel ridurre al minimo lo sforzo necessario per la costruzione di un traduttore. Idealmente, questo può essere ottenuto semplicemente estendendo il lessico e scrivendo un insieme di frasi esemplari per lo specifico contesto.
Le parti più interessanti dal punto di vista della ricerca scientifica in MOLTO sono due: l'interoperabilità tra gli standard per ontologie (tipo OWL) e le grammatiche GF, e l'estensione di metodi per la traduzione automatica basati sulle grammatiche con metodi di tipo statistico. L'interoperabilità OWL-GF consentirà un'interazione, in più lingue ed attraverso un linguaggio naturale, con l'informazione digitale. I metodi statistici aggiungono robustezza al sistema qualora sia necessario. Nuovi metodi di tipo ibrido verrano sviluppati per combinare grammatiche GF con traduzione statistica, a vantaggio di entrambi.
La tecnologia MOLTO verrà distribuita attraverso librerie open-source che potranno essere collegate a strumenti di traduzione standard e pagine web, e quindi si integreranno in metodologie e processi di lavoro standard. Il lavoro sarà presentato sul web e applicato in tre casi di studio: esercizi di matematica in 15 lingue, brevetti in ambito farmacologico in almeno 3 lingue, e descrizioni di oggetti museali (dipinti) in 15 lingue.
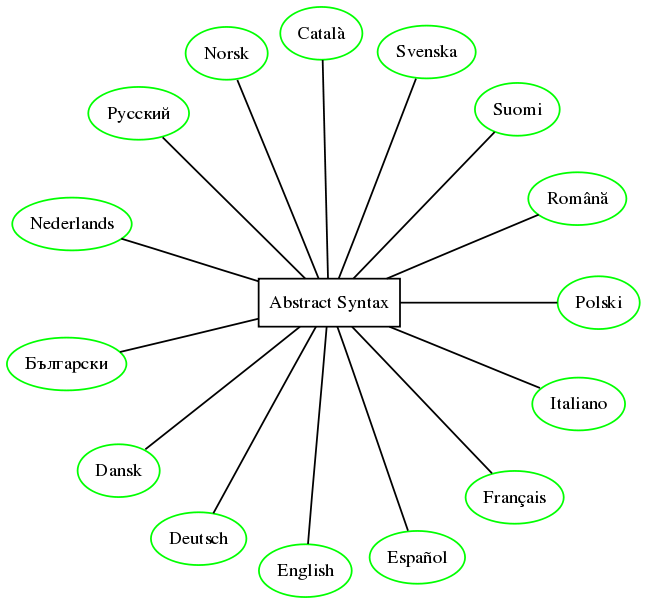
Le lingue in MOLTO
La traduzione automatica utilizza il sistema GF e la sua libreria di risorse grammaticale, che attualmente copre le lingue indicate in figura, sotto. Gli strumenti sviluppati da MOLTO consentiranno la specializzazione idiomatica in nuovi settori di applicazione di entrambi la sintassi astratta e dei frammenti di linguaggio.
Consorziati
- UGOT: Università di Göteborg, Svezia (coordinatore)
- Uhel: Università di Helsinki, Finlandia
- UPC: Universitat Politècnica de Catalunya, Barcellona, Spagna
- Ontotext: Ontotext AD, Sofia, Bulgaria
- BI: Be Informed, Apeldoorn, Paesi Bassi
- UZH: Università di Zurigo, Zurigo, Svizzera
Seguici
Per seguirci, iscriviti ai contenuti di MOLTO usando il sistema RSS o leggici con Twitter. Di tanto in tanto trasmettiamo in diretta il video di eventi organizzati dal progetto. Potete guardare sia su Ustream che su YouTube.
Contatti
Fateci sapere cosa ne pensate utilizzando il modulo per contattarci in rete.
What links here
No backlinks found.

